Developers often encounter a need for refactoring code that has existed for a long time. This is because software tends to get complex and unmaintainable over time, unless time and effort is spent on preserving the modular structure of the software and its simplicity in the face of evolving needs.
Martin Fowler defines refactoring as "... a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior". [Src]
A list of "refactorings" both from the original book by Fowler and some later sources, is available here.
Friday, November 26, 2010
Monday, November 15, 2010
jQuery 101 for folks on the run
Here is Rebecca Murphy's article on jQuery fundamentals. It helped me learn enough jQuery in a couple of days to do/understand small to medium sized jQuery based UIs.
Sreekanth, my good friend, has published a comparision between jQuery and GWT here.
Sreekanth, my good friend, has published a comparision between jQuery and GWT here.
Friday, October 15, 2010
Rebecca Wirfs-Brock's columns and articles on software design
Rebecca Wirfs-Brock's IEEE software "design" columns (published between Jan. 2006 and Dec. 2009) and several other articles on software design, can be found here. These are must reads for software designers/architects.
Wednesday, September 29, 2010
Floating Point Basics Made Easy
1) Introduction
Almost every processor, computer, programming language and operating system supports floating-points. Despite its ubiquity, most programmers consider it an esotoric topic. James Gosling (the "father" of Java) once asserted "95% of folks out there are completely clueless about floating-point."
The vast majority of applications/programs can do just with integral/integer types. There are times when the need to use non-integral types and the vagaries of representing those, show up. High-level programming languages such as Java, C#, C++ all make it very easy to use floating-points. However, seemingly innocuous floating-point code can cause severe discrepancies and very hard to debug runtime errors. Therefore, understanding how it works under the hood helps!
The basic ideas behind floating point are not very difficult to understand. This article intends to introduce the basics to the uninitiated. Folks interested in a deeper treatment of floating-point are referred to David Goldberg's article "What Every Computer Scientist Should Know About Floating-Point Arithmetic".
"Section 2" provides the background on topics such as real numbers, decimal and binary numeral systems. Readers already well-versed with these topics may want to just skim through this section. "Section 3" gets into the basics of floating-point representation. "Section 4" describes some practical issues in representing real numbers in floating point representation.
2) Background
2.1 Real Numbers
Nearly any number you can think of is a real number. This includes:- Whole numbers: {0 and natural/counting numbers: 1, 2, 3…..upto infinity}
- Negatives of counting numbers: {-infinity,….-3, -2, -1}
- Other rational numbers/fractions: Any number that can be expressed as a fraction m / n where m and n are integers and n is not equal to 0. Put another way, rational numbers are numbers that can be written as a simple fraction. For example 0.5, 7 and 0.214 are all rational numbers, since they can be represented exactly as: 1/2, 7/1 and 214/100 respectively.
- Irrational numbers: Any real number that is not a rational number, i.e., cannot be represented as a simple fraction. Some examples are:
- π ('Pi') = 3.14159....(and more). The popular approximation of 22/7 is close, but not accurate.
- √2 (Square root of 2) = 1.4142135623730950...(etc)
Note: A radix point is a symbol used to separate the the integer part of a number with from its fractional part. For e.g., in the number 1.23, the radix point (decimal point in this case) separates the integer 1 from the fraction 23.
2.2 Decimal Numeral System
The decimal number system that we use so frequently in our lives, has 10 digits (also known as decimal digits): 0, 1, 2, 3, 4, 5, 6, 7, 8 and 9. The "base" is the number of digits in a number system. So, the decimal number system is base-10 (has 10 as its base). The numbers 2525 or 25.25 use decimal digits, for example.The decimal number system allows you to represent a real number by an ordered set of characters where the value of the character depends on its position. When you say 2525, you implicitly mean 2x103 + 5x102 + 2x101 + 5 (which amounts to 2525). Therefore, it is a "positional" system of numeration.
A decimal fraction is a fraction where the denominator is a power of 10. For example 2.8 equates to 28/10, 0.28 equates to 28/(10x10).
2.3 Binary Numeral System
Unlike the decimal numeral system, which has 10 digits for representing characters in a number, most modern computers have only 0 or 1 to represent a number. Computers can be thought of as comprised of switches that are on or off (digital electronic circuitry using logic gates). These digits are called bits. Since there are only 2 digits available, the binary numeral system is a base-2 system.Like the decimal numeral system, the binary numeral system is a "positional" system of numeration, that is it represents a number by an ordered set of characters where the value of the character depends on its position.
Representing Positive Integers:
Suppose you want to represent the positive integers 12 and 139 (both decimal numbers) in the binary system. You can represent them in the binary system as follows:
12 = 1x23 + 1x22 + 0x21 + 0x20 = 1100
139 = 1x27 + 0 + 0 + 0 + 1x23 + 0 + 1x21 + 0 = 1000 1010
Notes:
- Bytes are sequences of 8 bits and are now used widely as a fundamental unit. Most modern computers process information in 8-bit units, or some multiples of 8 at a time: 16, 32, 64 bits. A group of 8 bits is also commonly known as octet. Individual bits are not directly addressable and are manipulated as part of bigger units such as bytes.
- As you can imagine, storing and processing the vast streams of bits can quickly become very inefficient. Moreover, it is tedious and error prone for system programmers to look at bits such as 1001001101110101 for debugging. Hexadecimal representation comes to the rescue. It is a compact representation of four bit groups and can be easily converted to the actual binary bits and back. A good description of hexadecimal is provided in [10].
So far we have seen how positive integers can be represented using the binary numeral system. Negative numbers are typically represented using two common approaches: "signed magnitude" and "two's complement".
"Signed magnitude" is simple: simply use the leftmost bit (the "most significant" bit - remember binary system is positional) for the sign – 0 for positive and 1 for negative. For example, on 8-bit numbers:
-12 = 1000 1100
+12 = 0000 1100
However, using signed magnitude mechanism complicates matters for circuit builders when they need to take a sign bit into account. The "two's complement" representation solves this problem and is widely used. To form a two's complement of a number, flip all bits and add 1. For example, to represent the number -13:
- Step 1: 13 = 0000 1101
- Step 2: Flip all bits => 1111 0010
- Step 3: Now add 1 (to represent negative sign) => 1111 0011
Representing -13 as 1111 0011 might look odd at first, but try adding 13 with +13 and you'd get zero as expected. The rules of binary arithmetic addition operation apply: carry to the next position if the sum of the digits and the prior carry is 2 or 3. Refer to [12] for a description on binary arithmetic.
11111 111
+13 0000 1101
-13 1111 0011
----------------
10000 0000
But only the last 8 digits count, so +13 and -13 add up to 0, as you'd expect.
Java's Primitive Integral Data Types:
At this point, you might want to see how the concepts we have discussed so far map to data types of a programming language. Let's take Java's Integer (also referred to as "integral") data types, as examples.
Data Type | No. of Bits/Bytes | Signed/Unsigned | Covers what values? |
boolean | 1 bit | NA | |
byte | 8 bits | Signed (two's complement) | -128 to 127 |
short | 2 bytes | Signed (two's complement) | -32,768 to 32,767 |
int | 4 bytes | Signed (two's complement) | -2,147,483,648 to 2,147,483,647 |
long | 8 bytes | Signed (two's complement) | 9,223,372,036,854,775,808 to +9,223,372,036,854,775,807 |
char | 2 bytes | Unsigned (Unicode) | 0 to 65,535 |
Representing Fractions:
In the decimal system, the value of each digit to the right of the decimal point (radix point) is calculated as 1/10, 1/102, 1/103, and so on. These equate to 10-1, 10-2, 10-3, and so on.
Similarly, in the binary system, the value of each successive digit of a binary fraction is the reciprocal of a power of 2 (1/2, 1/22, 1/23 … or 2-1, 2-2, 2-3).
As you know, there are only two digits/symbols in the binary system – both are used for representing the numerical value of the number. So, how do you represent the radix point?
One solution is to make the radix point implicit: for example, assuming that the radix point is in the middle of a given 16 bits format. 8 bits would be dedicated to representing the integer part and the remaining 8 bits would represent the fractional part. Consider the number 5.25, as an example.
- Integer portion 5: … 1x22 + 0x21 + 1x20 = 00000101
- Fraction portion .25 (=1/4): 0x2-1 + 2-2 = 01000000
| Decimal Number | Integer bits | Fractional bits |
| 5.25 | 00000101 | 01000000 |
Fixing the radix point and dedicating a fixed number of integer bits and fractional bits, is what is known as "fixed-point" representation. Fixed-point representations are used by most calculators, spreadsheets and some computer hardware/software.
Now, suppose you wanted to represent 5.25. The binary representation would be:
- 312 = 100111000 (9 binary digits)
- .25 = .01
Floating-point representations, on the other hand, do not use a fixed position for the radix point. It employs a scheme that contains a "floating" radix point (binary point in computers). We explore floating-point in the next section.
3) Floating-Point Numbers
There are times when you want to represent a number that is too large for your regular data types to handle. Say, you want to represent a very large number like 1x10100 or a very small number like the mass of an electron: 9.1x10-31. Enter floating-point representations.
Contrary to popular belief, floating-point representations are used to represent not only numbers that contain fractions, but also integers of large magnitudes. They essentially provide ability to represent a large dynamic range by means of an exponent while supporting reasonable accuracy by the use of a "mantissa"/"significand".
3.1 Floating Radix Points in Decimal Numeral System
Conventional scientific notation separates the position of the radix point from the significant digits. For example, the value 295.54 can be written as: 2.954 x 102, 29.54 x 10, etc.. In exponential form, the number can be written as 2.954E2, 29.54E1, etc.Similarly, one can represent an integer value 8 as a floating-point 8.00 (8E0), 0.8 x 10 (or 0.8E1), and so on.
Numbers smaller than 1 can be represented by using negative powers of 10. For example 0.5 = 5E-1 (represents 5x10-1) or 5E-2 (represents 50 x 10-2).
When you multiply or divide any of these numbers by 10 or any powers of 10, only the position of the decimal point (radix point) changes: the radix point "floats".
Now, say you have a large number such as 9,999,999,123. You can represent it as 0.9999999E10, as long as the loss of the three low-order digits doesn't cause much harm in your given scenario. But it does allow you to represent a much wider range of values: for example, 0.9999999E99.
3.2 Floating-Point in Binary Numeral System
In the last section we discussed how a given number can be represented in multiple ways in the decimal numeral system, simply by varying the radix point, and changing the exponent. A binary floating-point number works in a similar fashion.Let's consider the fractional number: + 11.1011 x 2-3 (or 11.1011E-3). It has:
- A positive sign: This represents whether the number is positive or negative.
- A Mantissa: 11.1001
- Where the integer part 11 = 21 + 20
- And the fractional part 1011 = 1/2 + 0 + 1/23 + 1/23 (can be also represented as: 2-1 + 0 + 2-3 + 2-3)
- An exponent 3. The value of the exponent is negative.
By varying the radix point and the exponent, one can represent a much wider range of numbers (both integers and fractions), even if the number of digits in the significand is much smaller than the range.
The most popular floating-point format is one defined by the IEEE 754 standard. The next sub-section describes the standard.
IEEE 754 Floating Point Formats:
Before the IEEE 754 standard was first published in 1985, there were several floating-point formats used by hardware and software. Therefore, it was difficult to port programs using floating-points from one system to another, as it would result in varying computed results.
The IEEE 754 specification is a widely adopted specification that describes how floating-point numbers are represented in binary (and decimal), how arithmetic operations and conversions needs to be done and how rounding and exception handling needs to be handled. It is widely adopted because it allows floating-point numbers to be stored in reasonable amount of space and computations to occur efficiently.
The standard defines five basic formats: a) three binary floating-point formats (which can be encoded in 32 bits, 64 bits and 128 bits), and b) two decimal floating-point formats. We explore the two key binary/base-2 floating-point formats: binary32 and binary64.
IEEE binary32 (also known as "single-precision" or "float" or "single") occupies 32 bits (4 bytes) in memory. It is implemented as "float" in Java, C, and C++, as "single" in Pascal and MATLAB, and as "real" in Fortran.
The layout of binary32 can be depicted as:
Sign Bit index: 31 (1 bit) | Exponent Bit index: 23-30 (8 bits) | Significand Bit index: 0-22 (23 bits) |
IEEE binary64 (also known as "double-precision" or "double") occupies 64 bits (8 bytes) in memory. It is implemented as "double" in Java, C++, C#, etc.
The layout of binary 64 can be depicted as:
Sign Bit index: 63 (1 bit) | Exponent Bit index: 52-62 (11 bits) | Significand Bit index: 0-52 (52 bits) |
Binary32 and binary64 have a similar layout and differ only on the number of bits devoted for the exponent and the significand.
- Sign Bit: The sign bit (the high-order bit in the above tables) represents whether the number is positive or negative. 0 represents a positive number and 1 represents a negative number.
- Exponent: The exponent represents the integer power of the base with which the significand must be multiplied.
The exponent needs to be able to represent both positive and negative exponents: positive for integer digits and negative for fractional digits, as we say earlier. Two's complement – the usual representation for signed values, would make comparison harder. Therefore, IEEE 754 standard establishes that the exponent be stored in biased form. A bias, in this context, refers to a constant that is added to the exponent in order to determine its final value.
Let's consider the single precision / binary32. Since the numerical range of 8 binary digits is 0 to 255 decimal, and half of this is approximately 127. Adding the constant 127 to all positive numbers would thus place them in the range 127-255. The negative exponents would fall in the range 1-126. Therefore, exponents of -126 to 127 are representable.
Exponents of -127 (all 0s) would be biased to 0, but is reserved to encode that the value is a denormalized number: a number that is very close to zero. It is also referred to as a "denormal". Denormalized numbers or denormals occur when the exponent of the number is too small to represent in the corresponding floating-point format. Why is the unbiased exponent of -127 reserved? Let us look at an example to illustrate the reason. The smallest non-zero normal number is 2-126. Now say, a = 1.01 x 2-126 x and b = 1.00 x 2-126. The computation (a –b) would result in an exponent 2-128 , which is not representable. This the computation would result in a value 0.0, which is not what you'd expect.
Similarly, exponents of +128 (all 1s) would be biased to 255, but are reserved for encoding an infinity or NaN (not a number).
- Infinities are generated by divisions by zero or by overflows. Overflows are generated when the result of an operation is a number so large in magnitude, that it cannot be represented. 1/0 = infinity, 1/inifinity = 0, and 0 (or any number) + inifinity = infinity.
- NaNs represent the result of operations that cannot have meaningful result in terms of a finite number or infinity. For e.g., 0/0 or √-1.
- Significant/Mantissa: The significand is also known by other names too: mantissa, significant digits, fractional part, etc. We saw earlier that any given number, in base-2 or base-10, can be represented in multiple ways.
Floating point numbers are "normalized" such that they are represented as a base-2 decimal with a digit 1 to the left of the radix point, adjusting the exponent as necessary. Since every number (except for denormals) is represented with 1 is the first digit of the significand, IEEE 754 implementations can assume the bit, i.e., the first digit does not need to be stored explicitly. In the normalized form, the integer portion (the left of the radix point) is exactly one bit. Therefore, all stored digits in the bits dedicated to the significand hold only fractional parts. Refer to [13] page numbers 49-50, for a nice description on how a floating-point binary number is converted into a normalized form.
Also, by assuming a leading bit 1, the IEEE 754 single- and double- precision formats double the range of the representation. Rhe normalized significand's range is 1.00000… (all 0s, since 1 is assumed) to 1.111111… (all 1s, since 1 is assumed). The subnormals range from 0.0000…1 to 0.1111….
(-1)-sign x mantissa x 2 (exponent-127)
Let's take an example of a decimal number -55.625 to illustrate the above concepts.
- Since the number is negative, the sign is 1.
- 55.625 can be represented in binary/base 2 as 110111.101 (equates to the integer: 32 + 16 + 0 + 4 + 2 + 1, and the fraction: 0.5 + 0 + 0.125).
- Normalizing the binary value, we get 1.10111101 and exponent 5 (base 2). The significand is 1.10111101. The fraction is: .10111101.
- Now, apply the bias to the exponent 5: this results into 132 (5+127).
Sign | Exponent | Significand |
1 | 10000100 | 1011110100000000000000 |
The effective ranges (excluding infinite values) of IEEE floating-point numbers are [17]:
Binary Range | Decimal Range | |
| Single Precision/ binary32 | ± (2-2-23) × 2127 | ~ ± 1038.53 |
| Double Precision/ binary64 | ± (2-2-52) × 21023 | ~ ± 10308.25 |
If you printed Java's minimum and maximum values for the corresponding float and double data types, you would get:
Float.MIN_VALUE = 1.4E-45 and Float.MAX_VALUE = 3.4028235E38
Double.MIN_VALUE = 4.9E-324 and Double.MAX_VALUE = 1.7976931348623157E308
4) Practical Issues in Representing Numbers
We now turn to some of the errors that can occur when we try to represent a given real number in the binary form.
4.1 Bit Patterns are Finite, Real Numbers are Not
Real numbers have the following properties (among others):- They have no upper and lower bounds: they go from –infinity to +infinity.
- They have infinite density: There is a real number between any two real numbers. Consider 1.1 and 1.2. There are infinite real numbers between the two: 1.11, 1.111, 1.12, 1.112… and so on.
1111 1111 = 27 + 26+ 25 + 24 + 23 + 22 + 21 + 20 = (128 + 64 + 32 + 16 + 8 + 4 + 2 + 1) = 256
Thus, using all 8 bits, you can get 256. In general, if you have n bits available, you have at most 2n bit-patterns, and so you can represent at most 2n numbers. For example, using Java's 32 bits integer data type "int", you can represent at most 232 integers.
Most data types have a finite set of bits and as such the type will have to have a largest number and a smallest number (bounded). Also, computations must also not exceed the bounds.
4.2 Not all Real Numbers Are Representable Exactly
In the decimal numeral system (base-10), fractions such as 1/2, 1/4 and 1/5 can be represented exactly as 0.5, 0.25 and 0.2, respectively. There are others (irrational numbers) that cannot be represented exactly. For example: 1/3 = 0.333333333333333333… (3 repeats infinitely), 1/7 = 0.14285714285714285714285714285714… (and so on).In the decimal numeral system, any decimal fraction whose value can be found with a sum of finite number of inverse power or 10, can be represented exactly as a decimal fraction. Others can't be represented exactly.
Similarly, in the binary system, some decimal numbers such as 0.5 are exactly representable ( 0.5 equates to 1/2). There are others such as 0.1 and 1/5 that cannot be represented exactly.
For example, the decimal value 0.1 can be represented roughly as a base 2 fraction 0.0001100110011001100110011001100110011001100110011..., where the fraction repeats inifinitely. Stop at any finite number of bits, and what you have is an approximation, rather than the exact value. For binary representations, any decimal fraction whose value cannot be found with a sum of finite number of inverse powers of 2, cannot be represented exactly.
4.3 Floating-Point Rounding Errors are Unavoidable
Arithmetic computations with integers are exact, except when they result in "overflows" (the result is outside the range of integers that can be represented. In contrast, floating point arithmetic is often not exact, because there are real numbers that cannot be represented exactly (as we discussed earlier) and so, must be approximated or "rounded off".These roundoff errors can show up in unexpected ways, if you are not careful. Take the following code written in Java for an example.
double i=0.0;
while (i != 0.1) {
i = i+0.01;
}
The while-loop in the above code will run infinitely, even though your expectation may be it should loop only 10 times. You can fix the code by changing "i !=0.1" to "i<=0.1".
Let's look at another example:
double finalval = 0;
for (int i=0; i<10; i++) {
finalval +=0.1;
}
System.out.println(finalval);
if (finalval == 1.0) {
// do whatever
}
The 'finalval' in the above example is not computed as 1.0 as you'd expect. It is: 0.9999999999999999. So, the code within the if block below that checks does an exact comparision is not executed.
Refer to [14, 15] for other great examples.
5) Summary
A floating point number is a finite representation that is designed to approximate (and not always represent exactly) a real number. It enables you to represent a much larger range of numbers, both integers and decimal fractions. Floating-point representation is done by breaking up a number into a fractional part and an exponent part and storing the parts separately.
By varying the radix point and the exponent, one can represent a much wider range of numbers (both integers and fractions), even if the number of digits in the significand is much smaller than the range. The most widely adopted floating-point standard is IEEE 754 and most software, including programming languages, implement the two binary formats defined by the standard: binary32 and binary64. A single-precision floating point number, i.e., binary32, contains 32 bits: 1 bit for the sign, 8 bits for the exponent and 23 bits for the significant digits. A double-precision floating point number, i.e., binary64, contains 64 bits: 1 bit for the sign, 11 bits for the exponent and 23 bits for the significant digits.
Although one does not need to know all the details of floating-point arithmetic used in hardware and software, having a basic understanding of how floating-point works makes it easier to represent real numbers, avoid potential issues due to rounding errors, and debug floating-point code.
6) References
[1] David Goldberg, "What Every Computer Scientist Should Know About Floating-Point Arithmetic"
[2] Brian Goetz, "Java Theory and Practice: Where's your Point?", Jan 2003
[3] http://en.wikipedia.org/wiki/Fixed-point_arithmetic
[4] Ronald Mak, "Java number cruncher: the Java programmer's guide to numerical computing", Prentice Hall PTR, 2003
[5] http://en.wikipedia.org/wiki/IEEE_754
[6] http://en.wikipedia.org/wiki/Computer_numbering_format
[7] David Monniaux, "The Pitfalls of Verifying Floating-Point Computations", May 2008
[8] http://www.mathsisfun.com
[9] Horstmann, Cay. "Appendix K - Number Systems". Big Java, Third Edition. John Wiley & Sons. © 2008
[10] Daniel B. Sedory, "What is Hexadecimal? And Where/How/Why is it used in Computers?"
[11] http://www.ibiblio.org/pub/languages/fortran/ch4-1.html
[12] http://en.wikipedia.org/wiki/Binary_numeral_system
[13] Julio Sanchez & Maria P. Canton, "Microcontroller Programming: The Microchip PIC", CRC Press
[14] Robert Sedgewick Kevin Wayne, "Introduction to Programming in Java", "9.1 Floating Point", http://www.cs.princeton.edu/introcs/91float/
[15] Bruce M. Bush, "The Perils of Floating Point", 1996
[16] Steve Hollasch, "IEEE Standard 754 Floating Point Numbers", 2005
Tuesday, September 28, 2010
Friday, August 27, 2010
Java concurrency guidelines
Thursday, August 05, 2010
Eponymous laws
Eponymous laws are adages, laws, principles, theorems, etc. named after a person. Wikipedia has a fabulous list of such laws here.
A few from the above list (taken as is) that may be of interest to folks in software engineering:
A few from the above list (taken as is) that may be of interest to folks in software engineering:
- Amara's law — "We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run."
- Brooks' law — "Adding manpower to a late software project makes it later." Named after Fred Brooks, author of the well known book on Project Management, The Mythical Man-Month.
- Campbell's Law - "The more any quantitative social indicator is used for social decision-making, the more subject it will be to corruption pressures and the more apt it will be to distort and corrupt the social processes it is intended to monitor." Named for Donald T. Campbell (1916 - 1996)
- Classen's law — Theo Classen's "Logarithmic Law of Usefulness" - 'usefulness=log(technology)'.
- Conway's Law — "Any piece of software reflects the organizational structure that produced it." Named for Melvin Conway.
- Dilbert Principle — Coined by Scott Adams as a variation of the Peter Principle of employee advancement. Named after Adams' Dilbert comic strip, it proposes that "the most ineffective workers are systematically moved to the place where they can do the least damage: management."
- Gall's law — "A complex system that works is invariably found to have evolved from a simple system that worked."
- Gibrat's law — "The size of a firm and its growth rate are independent."
- Godwin's law — An adage in Internet culture that states, "As an online discussion grows longer, the probability of a comparison involving Nazis or Hitler approaches one." Coined by Mike Godwin in 1990.
- Goodhart's law — "When a measure becomes a target, it ceases to be a good measure."
- Kranzberg's First Law of Technology — "Technology is neither good nor bad; nor is it neutral."
- Linus' law — "Given enough eyeballs, all bugs are shallow." Named for Linus Torvalds.
- Murphy's law — "Anything that can go wrong will go wrong." Ascribed to Edward A. Murphy, Jr.
- Pareto principle — States that for many phenomena 80% of consequences stem from 20% of the causes. Named after Italian economist Vilfredo Pareto, but framed by management thinker Joseph M. Juran.
- Rothbard's law — "Everyone specializes in his own area of weakness."
- Sayre's law — "In any dispute the intensity of feeling is inversely proportional to the value of the stakes at issue."
- Wirth's law — "Software gets slower faster than hardware gets faster."
- Dunning-Kruger Effect - Per this Wikipedia article: "... is a cognitive bias in which an unskilled person makes poor decisions and reaches erroneous conclusions, but their incompetence denies them the metacognitive ability to realize their mistakes. The unskilled therefore suffer from illusory superiority, rating their own ability as above average, much higher than it actually is, while the highly skilled underrate their abilities, suffering from illusory inferiority".
Saturday, July 10, 2010
Computer and software history
Cicero (Roman author, orator, & politician - 106 BC - 43 BC) is quoted to have said: "History is the witness that testifies to the passing of time; it illumines reality, vitalizes memory, provides guidance in daily life and brings us tidings of antiquity."
For those interested in the history of computers: The Computer History museum, located here on the Web, is dedicated to preserving and presenting the stories and artifacts of the information age. It was established in 1996 in Mountain View, California, USA. Also checkout videos of the many lectures and events at the museum and historic computer films, hosted on Youtube.
The museum has a special interest group on software history. Besides the history of software since the 1950s it has interesting anecdotes, first person essays, etc.
Keep in mind though, the Website is still in the making.
For those interested in the history of computers: The Computer History museum, located here on the Web, is dedicated to preserving and presenting the stories and artifacts of the information age. It was established in 1996 in Mountain View, California, USA. Also checkout videos of the many lectures and events at the museum and historic computer films, hosted on Youtube.
The museum has a special interest group on software history. Besides the history of software since the 1950s it has interesting anecdotes, first person essays, etc.
Keep in mind though, the Website is still in the making.
Friday, July 02, 2010
Rift between business and IT
Found this particularly hilarious picture on one of Anne Thomas Manes' slides set (don't remember which one though).


Thursday, July 01, 2010
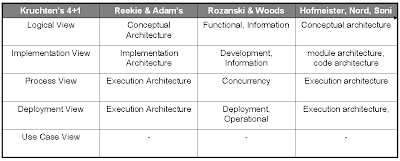
Mappings Among Architecture View Sets
This is my take on how some of the popular view sets map to each other:

Friday, June 11, 2010
"Selling" and "Order Handling" Overview (Communications Service Provider Environment)
I often get queries related to basic aspects of selling and order handling business processes from teams that I work with. Here is a brief (very brief) overview of these processes, using TeleManagement Forum's Business Process Framework (widely known as eTOM) as a reference.
In sales terminology, a potential or a likely customer is called a "prospect". Prospects are typically determined by one of the following:

g) Manage sales accounts: This sub-process is responsible for managing sales accounts assigned to a sales channel and/or manager [Etom_Gb921]. These accounts are then used on a regular basis to develop appropriate relationships and contacts, to prospect for leads for other offerings, or to offer specific discounts based on criteria such as sales volume, length of relationship, etc.

2. Order Handling
Once a sales contract has been signed by the customer, its time to create and process customer orders for fulfilling the services that form the product offering. Enter order handling.
Although the terms product offerings and services are often used interchangeably, they have separate meanings. As described by [McFadyen], "This is best thought of as the box that everything is put in. Just as when you buy cornflakes it is the flakes of corn you want inside the box, but it is the box with its logo, brand name, and barcode that you actually purchase." The "flakes of corn" is the service while the "box of cornflakes" is the product offering. From the viewpoint of a product manager, a product offering defines what functionality is provided at what price to which market segments over which sales channel. A service on the other hand is the functionality that the customer gets. Product offerings can get complex in that many different services may be combined in a single offering bundle to make it attractive (cost-effective, for e.g.).
eTOM classifies key order handling processes/activities as:

The sub-processes within order handling are:
a) Determine preorder feasibility – This sub-process is responsible for determining whether the standard/customized product offering chosen for the customer is available and/or feasible. Examples of such checks include (but are not limited to):
c) Issue customer order – This sub-process ensures that all necessary information about the customer order is captured and validated and that the customer has been issues a sales order. This sub-process typically kicks in after a purchase order has been received by the service provider.
A purchase order (PO) is a commercial document issued by a buyer to a seller, indicating types, quantities, and agreed prices for products or services the seller will provide to the buyer [Wikipedia_po], and constitutes a legal offer to buy products or services. Acceptance of the PO by the seller (service provider in this context) forms a contract between the buyer and the seller. A PO ensures the service provider is protected in case of a customer's refusal to pay for agreed products or upon unilateral cancelling of the order [Wikipedia_po].
A sales order (SO), on the other hand, is an order issued by the seller (service provider in this context) to the buyer (customer). Information captured as part of the sales order may include originating PO (one or more), service locations, product configuration data (such as bandwidth, circuit speed, etc.), bill-to customer account, customer contacts, and so forth. Both the customer and the service provider use the issued order to track the status, make edits to the order, etc.
d) Track and manage customer order handling – The objective of this sub-process is to ensure customer provisioning activities are assigned, managed and tracked efficiently to meet the committed availability date [Etom_Gb921]. This includes scheduling activities, generation of respective service order creation requests, tracking orders, adding additional information to existing customer order, cancelling customer order, monitoring jeopardy status of customer orders and escalating customer orders as necessary [Etom_Gb921].
e) Complete customer order – This process is responsible for ensuring that any customer information required by any other processes is updated as part of customer order completion [Etom_Gb921]. This may involve additional touch points with the customer. This may also involve sending relevant notifications to the customer on events such as service provider's acceptance of the order, commitment date, etc.
f) Report customer order handling – The objective of this sub-process is to monitor the status of customer orders, provide notifications of any changes and provide management reports [Etom_Gb921]. Specialized notifications to customers may include those indicating service provider's validation and acceptance of the order, availability date of the services, completion of the provisioning, activations of the respective services, etc.
g) Close customer order – The objective of this sub-process is to close a customer order when the customer provisioning activities have been completed.
As mentioned earlier, eTOM doesn't specify how the sub-processes are sequenced.
References
[McFadyen] Andrew McFadyen, http://telecomseim.blogspot.com/
[Etom_Gb921] GB921 Addendum D-Process Decompositions & Descriptions, Business Process Framework (eTOM), R 8.0, TeleManagement Forum (TM Forum), June 2009
[Wikipedia_po] http://en.wikipedia.org/wiki/Purchase_order
[TargusInfo] "Turning Prospects into Profits", TargusInfo, 2009
1. Selling
In sales terminology, a potential or a likely customer is called a "prospect". Prospects are typically determined by one of the following:
- Leads – These are typically determined by product marketing teams and decision analytics systems supporting product marketing. For e.g., responses from email-, direct- or tele-marketing campaigns may provide good leads to potential customers. Similarly, website analytics tools may be used to analyze web page hits from a particular region to determine prospects.
- Referrals – The customer might indicate an interest to a branch or call center representative who then directs the referral to sales specialists. Service providers also provide customer portals where customers can register an interest.
- Transaction-Based Triggers – Prospects may also be determined by transaction-based activities combined with decision analytics. For e.g., based on customer's long distance calling pattern and its availability to a sales rep, the sales rep may be able to suggest a higher value unlimited long distance plan.
Prospects are turned into opportunities for further processing through the sales-pipeline, based on a number of factors, including but not limited to [TargusInfo]:
- Which prospects are most likely to convert?
- What is a prospect's potential lifetime value?
- What size order would the prospect place if she were to become a customer?
The sales-pipeline supports the key selling related functions such as analysis of customer needs, identification of respective product offerings, sales-negotiation, quotes, proposals, sales forecast, etc. eTOM classifies key selling sub-processes as illustrated in Figure 1 below.

The sub-processes within "Selling" in eTOM are:
a) Manage prospect: This sub-process is responsible for matching assigned leads with the most appropriate products and ensuring that the prospects are handled appropriately [Etom_Gb921]. Activities include capturing and processing the probability of successful sales closure, estimating the total attainable revenue, analyzing the needs of the prospect, identifying potential solutions from the service provider's portfolio, etc.
b) Qualify opportunity: This sub-process ensures that the opportunity is qualified in terms of any associated risk, and the amount of effort required (e.g., response to a RFP vs. potential revenue) to achieve a sale [Etom_Gb921]. Also, customer's needs are analyzed and matched against available product offerings or customized solutions.
c) Negotiate sales/contract: Customers may agree with the standard prices and promotions or may want to negotiate pricing. For example, although the sales rep may have already offered 5% discount, the customer might be looking for a 12% discount. Also, the customer may want to negotiate non-standard terms and conditions/contracts. This sub-process includes activities supporting sales and contract negotiation.
d) Acquire customer data: This involves collection, association and organization of all pertinent data related to the customer, including those that are required to support the agreed product offerings and contract.
e) Cross/up selling: The purpose of this sub-process is to ensure that the value of the relationship between the customer and service provider is maximized by selling additional, or more of the existing products [Etom_Gb921]. Additionally, the ongoing analysis of customer's usage, problems or complaints can be used to identify when the current products may no longer be appropriate for the customer, or an opportunity for a larger sales arise [Etom_Gb921].
f) Develop sales proposal: The purpose of this sub-process is to develop a sales proposal to respond to customer's requirements [Etom_Gb921]. The development of a sales proposal may require selection of standard a product offering or may require the development of a non-standard offering [Etom_Gb921], leading to development of a unique solution design.
Note that the sub-processes defined in eTOM, as shown in Figure 1 above, are in no particular sequence. eTOM refrains from defining sequencing of these processes as different service providers may need to implement them in different sequences, based on their particular environment. Figure 2 below depicts a sample flow that might be applied in a service provider environment.

Once a sales contract has been signed by the customer, its time to create and process customer orders for fulfilling the services that form the product offering. Enter order handling.
Although the terms product offerings and services are often used interchangeably, they have separate meanings. As described by [McFadyen], "This is best thought of as the box that everything is put in. Just as when you buy cornflakes it is the flakes of corn you want inside the box, but it is the box with its logo, brand name, and barcode that you actually purchase." The "flakes of corn" is the service while the "box of cornflakes" is the product offering. From the viewpoint of a product manager, a product offering defines what functionality is provided at what price to which market segments over which sales channel. A service on the other hand is the functionality that the customer gets. Product offerings can get complex in that many different services may be combined in a single offering bundle to make it attractive (cost-effective, for e.g.).
eTOM classifies key order handling processes/activities as:

The sub-processes within order handling are:
a) Determine preorder feasibility – This sub-process is responsible for determining whether the standard/customized product offering chosen for the customer is available and/or feasible. Examples of such checks include (but are not limited to):
- Can the corresponding services be provisioned at the given location?
- Are there enough circuits or lines available in the given region?
- Can the services meet the specified SLA based on current network environment?
c) Issue customer order – This sub-process ensures that all necessary information about the customer order is captured and validated and that the customer has been issues a sales order. This sub-process typically kicks in after a purchase order has been received by the service provider.
A purchase order (PO) is a commercial document issued by a buyer to a seller, indicating types, quantities, and agreed prices for products or services the seller will provide to the buyer [Wikipedia_po], and constitutes a legal offer to buy products or services. Acceptance of the PO by the seller (service provider in this context) forms a contract between the buyer and the seller. A PO ensures the service provider is protected in case of a customer's refusal to pay for agreed products or upon unilateral cancelling of the order [Wikipedia_po].
A sales order (SO), on the other hand, is an order issued by the seller (service provider in this context) to the buyer (customer). Information captured as part of the sales order may include originating PO (one or more), service locations, product configuration data (such as bandwidth, circuit speed, etc.), bill-to customer account, customer contacts, and so forth. Both the customer and the service provider use the issued order to track the status, make edits to the order, etc.
d) Track and manage customer order handling – The objective of this sub-process is to ensure customer provisioning activities are assigned, managed and tracked efficiently to meet the committed availability date [Etom_Gb921]. This includes scheduling activities, generation of respective service order creation requests, tracking orders, adding additional information to existing customer order, cancelling customer order, monitoring jeopardy status of customer orders and escalating customer orders as necessary [Etom_Gb921].
e) Complete customer order – This process is responsible for ensuring that any customer information required by any other processes is updated as part of customer order completion [Etom_Gb921]. This may involve additional touch points with the customer. This may also involve sending relevant notifications to the customer on events such as service provider's acceptance of the order, commitment date, etc.
f) Report customer order handling – The objective of this sub-process is to monitor the status of customer orders, provide notifications of any changes and provide management reports [Etom_Gb921]. Specialized notifications to customers may include those indicating service provider's validation and acceptance of the order, availability date of the services, completion of the provisioning, activations of the respective services, etc.
g) Close customer order – The objective of this sub-process is to close a customer order when the customer provisioning activities have been completed.
As mentioned earlier, eTOM doesn't specify how the sub-processes are sequenced.
References
[McFadyen] Andrew McFadyen, http://telecomseim.blogspot.com/
[Etom_Gb921] GB921 Addendum D-Process Decompositions & Descriptions, Business Process Framework (eTOM), R 8.0, TeleManagement Forum (TM Forum), June 2009
[Wikipedia_po] http://en.wikipedia.org/wiki/Purchase_order
[TargusInfo] "Turning Prospects into Profits", TargusInfo, 2009
Thursday, May 13, 2010
Paul Graham on Startups
Paul Graham is famous for his plain-spoken, deeply insightful and thought-provoking essays. Some of his essays on startups:
- "What Startups are Really Like"
- "How to Start a Startup"
- "The Hardest Lessons for Startup to Learn"
- "How to fund a Startup"
- "Ideas for Startup"
- "The 18 Mistakes that Kill Startups"
- "A Fundraising Survival Guide"
Subscribe to:
Posts (Atom)


